At FP Complete we develop many tools for our clients to help them achieve their goals. Most of these tools are written in Haskell (and, more recently, some are in Rust), and that has helped us write them more quickly and produce more maintainable apps going forward.
In this post I would like to describe one of those tools which should be of interest to any person or company which has a present or legacy database with SQL server.
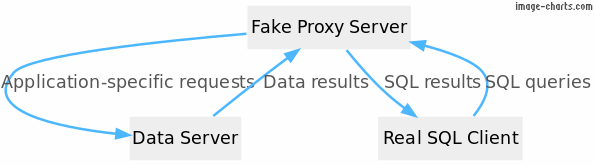
A client was migrating from SQL Server to PostgreSQL across the board, however, like in many large companies, they had many databases spread across the country in different servers and used by many people in different departments. It is not so easy to simply replace a database that many people are using directly. They still wanted to provide a SQL Server query interface to their various departments, so they asked us whether we could develop a standalone service that could pretend to be SQL Server but really talk to any JSON service behind the scenes. We did! This article takes a look at how it was done.
The high-level architecture of the system looks like this:
Requirements:
WHERE clause).So, a user of the system would write a regular SQL Server query,
such as SELECT * FROM "customer" and that would be
sent to a fake SQL server, which in turn would query the real
background service, whatever that is, and return results back to
the user.
In order to implement a fake SQL Server, we need:
I looked into the protocol used by SQL Server and its clients. It’s called TDS, which means “tabular data stream”. It was initially designed and developed by Sybase Inc. for their Sybase SQL Server relational database engine in 1984. Later it was adopted by Microsoft for Microsoft SQL Server. It is a fairly straightforward binary protocol, as binary protocols go. Microsoft have documentation for the TDS protocol, which you can eyeball in your own time.
Regarding a client program, today it is much easier to get access to Microsoft client libraries in Linux or Mac OS X, thanks to their releases of their ODBC package. You can now get it on Linux and macOS! I was surprised too! This made it easy to write a test suite for our server.
TDS is a binary protocol. Communication is done using messages, where each message is a sequence of so-called packets, each consisting of a header and (usually, but not always) a payload:
Packet
| Header | Payload |
|---|
The header is 8 bytes long and described by the table below. I’ve crossed out the ones we don’t use.
Header
| Field | Type | Description |
|---|---|---|
|
|
Word8 | Not used by us |
| Status | Word8 | 0 = normal message, 1 = end of message |
| Length | Word16 | Length of packet big endian |
|
|
Word16 | Not used by us |
|
|
Word8 | Not used by us and ignored by SQL Server |
|
|
Word8 | Not used, should be ignored |
It turns out we only need the status and
length fields!
Status tells us whether there are more packets in
this request or whether this is the final one.Length tells us the length of the whole packet,
including the header itself.A typical scenario:
For example:
We dealt with both types of messages, but we’ll just look at simple batch queries in this article.
stack-column-center
My second step was to start up a Haskell project and plan the libraries that I would use for this task.
I used these Haskell packages:
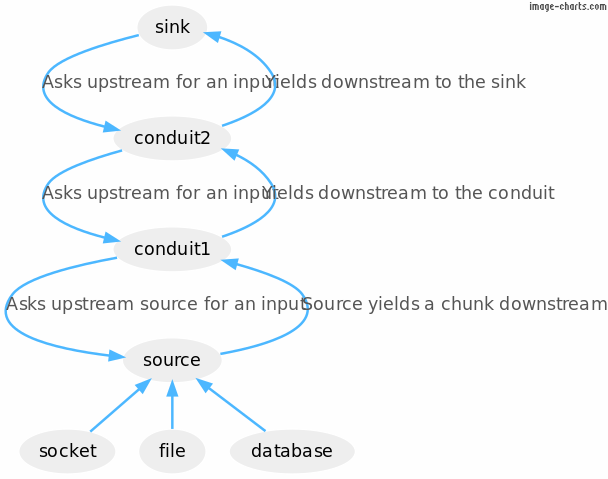
In diagram form, that pipeline looks like this:
We’ll look at each one in detail.
Conduit is used to achieve streaming. Other languages such as Rust call these iterators, or in Python they are called generators (data producers) and coroutines (data consumers). In Haskell it’s implemented as a normal library. It is a conceptually simple streaming API, consisting of two really key pieces:
await – stop whatever you’re doing and wait for
the next chunk in the Stream.yield – provide a chunk to the await
downstream.We make use of these things in the server and so do all the libraries that I use for this task.
Consider this example pipeline,
pipeline =
source .| conduit1 .| conduit2 .| sink
(Note: the .| can be read like a UNIX pipe.)
The source may be a socket, a file or a database. These three kinds of I/O sources of chunks can yield bytes, or e.g. rows from a database query. In a conduit pipeline, the sink (the final thing in the pipeline) drives the computation, creating a domino effect back down the pipline every time it awaits for input, all the way back to the source, which consults some external provider (the socket, file or database).
I used conduit-extra because you can put together a listening service in about 3 lines. That looks like this:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import Data.Conduit.Network
import Conduit
main =
runTCPServer
(serverSettings 2019 "*")
(app -> do
putStrLn "Someone connected!"
runConduit (appSource app .| mapMC print .| sinkNull)
putStrLn "They disconnected!"
pure ())
In this example, the source conduit coming from the socket is
piped into a conduit (mapMC print) that just prints
each chunk coming in. Finally, that’s piped to
sinkNull which consumes all its input and discards
it.
Running it looks like this:
$ ./conduit-tcp-server.hs
Someone connected!
"hin"
They disconnected!
We’re going to build up a simple example server incrementally.
If you want to follow along and run these Haskell examples on
your computer, they can be run conveniently as regular scripts when
you have stack installed. Check out our get started page
and follow the instructions to get setup.
Most libraries in Haskell pride themselves on type-safety and streaming libraries like Conduit are no exception. Let’s have a brief look at that. This is the type for a conduit:
data ConduitT input output monad return
It means “a conduit has an input, an
output, runs in some monad, and has a
final return value”.
So for example, yield has this type:
yield :: Monad m => input -> ConduitT input output monad ()
It yields an input downstream, and returns unit
().
Whereas await has this type:
await :: Monad m => ConduitT input output monad (Maybe output)
It awaits for an output from upstream, and might return
Just that, if there is anything left upstream.
Otherwise it returns Nothing.
A function like map and filter also
have educational types:
map :: Monad m => (input -> output) -> ConduitT input output monad ()
filter :: Monad m => (input -> Bool) -> ConduitT input input monad ()
Finally, plugging them together has to have the correct types:
filter (> 5) .| map show .| filter (=/ "6") .| ...
This lets us plug pieces together like LEGO bricks, confident that our composition is correct. The inputs, outputs and returns all have to match up.
I used attoparsec to parse the binary protocol. attoparsec is a parser combinator library which supports incomplete parsing of input i.e. parsing data in chunks.
Here’s a simple, closed example:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
main =
case P.parseOnly myparser (S.pack [2, 97, 98]) of
Right result -> print result
Left err -> putStrLn err
where
myparser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
Which outputs the following:
$ ./attoparsec-example.hs
"ab"
If I create a streaming program that feeds one-byte chunks into the parser like this:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
main = loop (P.parse myparser) (S.pack [2, 97, 98])
where
loop eater input =
do putStrLn ("Chunk " ++ show (S.unpack chunk))
case eater chunk of
P.Done _ value -> print value
P.Fail _ _ err -> putStrLn err
P.Partial next -> do
putStrLn "Waiting for more ..."
loop next remaining
where (chunk, remaining) = S.splitAt 1 input
myparser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
We create a loop with an “eater”. The eater eats chunks of bytes. It produces either a done/fail result, or the next eater that is ready for the next chunk.
The output is:
$ ./attoparsec-feeding.hs
Chunk [2]
Waiting for more ...
Chunk [97]
Waiting for more ...
Chunk [98]
"ab"
Note however that myparser didn’t change. It
doesn’t care how the input is chunked. It’s patient. The end result
is the same. This works very well with conduit, and naturally,
conduit has integration with attoparsec from the conduit-extra
package.
The above code can be rewritten in conduit as:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
import Conduit
import Data.Conduit.List
import Data.Conduit.Attoparsec
main = do
result <- runConduit (sourceList chunks .| sinkParserEither myparser)
case result of
Left err -> print err
Right val -> print val
where
chunks = [S.pack [2], S.pack [97], S.pack [98]]
myparser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
Producing:
$ ./attoparsec-conduit.hs
"ab"
Looking at this example and the one above it, it’s easy to
imagine how sinkParserEither operates. It consumes
chunks from the upstream, and incrementally feeds them to
myparser until a result happens.
Finally, to generate messages for the TDS protocol, I can efficiently generate binary streams using the bytestring Builder abstraction. Essentially, this abstraction let you insert strings of bytes into a buffer and they are appended efficiently. Additionally, these can be written to a socket or file incrementally in a streaming fashion, and therefore are also memory efficient.
Specifically for our use-case, it makes it trivial to output a binary format that involves word8s, word16s and to differentiate little-endian vs big-endian encodings easily.
For example to build our example above, we’d use
<> to combine chunks together:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString.Lazy as L
import qualified Data.ByteString.Builder as BB
main = L.putStr (BB.toLazyByteString (BB.word8 2 <> "ab"))
$ ./builder-example.hs
ab
Or it can be written as a conduit:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import System.IO
import Data.Conduit
import qualified Data.Conduit.List as CL
import qualified Data.Conduit.Binary as CB
import qualified Data.ByteString.Lazy as L
import qualified Data.Conduit.ByteString.Builder as CB
import qualified Data.ByteString.Builder as BB
main =
runConduitRes
(CL.sourceList [BB.word8 2 <> "ab"] .| CB.builderToByteString .|
CB.sinkHandle stdout)
That is, produce a source of a builder. Feed it to a conduit which converts builders to streams of bytestrings, then feed that to a sink that writes to stdout.
With all that in mind, the message parser looks like this:
messageParser :: Parser (Packet ClientMessage)
messageParser = do
header <- headerParser
let payloadLength = fromIntegral (headerLength header - headerSize)
message <-
case headerType header of
0x01 -> sqlbatchParser payloadLength
0x12 -> preloginParser payloadLength
0x0E -> transactionParser
0x03 -> rpcParser payloadLength
0x10 -> loginParser
0x06 -> attentionParser
_ -> do
payload <- Atto.take payloadLength
pure (UnknownMessage payload)
pure (Packet header message)
For example, sqlbatchParser is
sqlbatchParser :: Int -> Parser ClientMessage
sqlbatchParser messageLen = do
start <- parserPosition
_headers <- allHeadersParser
end <- parserPosition
text <- Atto.take (messageLen - (end - start))
pure (SQLBatchMessage (T.decodeUtf16LE text))
We actually ignore the headers and are just interested in the SQL query. We grab that from the stream and decode it as UTF16 little-endian, which is the specified text format for TDS.
An example looks like this, in hex editor format:
01 01 00 5C 00 00 01 00 . . . \ . . . .
16 00 00 00 12 00 00 00 . . . . . . . .
02 00 00 00 00 00 00 00 . . . . . . . .
00 01 00 00 00 00 0A 00 . . . . . . . .
73 00 65 00 6C 00 65 00 s . e . l . e .
63 00 74 00 20 00 27 00 c . t . . ' .
66 00 6F 00 6F 00 27 00 f . o . o . ' .
20 00 61 00 73 00 20 00 . a . s . .
27 00 62 00 61 00 72 00 ' . b . a . r .
27 00 0A 00 20 00 20 00 ' . . . . .
20 00 20 00 20 00 20 00 . . . .
20 00 20 00 . .
Or in tabular format:
| Part | Contents | Meaning |
|---|---|---|
| Type | 01 | SQL Batch request |
| Status | 01 | Last packet |
| Length | 00 5C | 92 |
| SPID | 00 00 | 0 |
| Packet | 01 | 1 |
| Window | 00 | 0 |
| Headers | 16 00 00 00 12 00 00 00 02 00 00 00 00 00 00 00 00 01 00 00 00 00 | Not important |
| SQL | 0A 00 73 00 65 00 6C 00 65 00 63 00 74 00 20 00 27 00 66 00 6F 00 6F 00 27 00 20 00 61 00 73 00 20 00 27 00 62 00 61 00 72 00 27 00 0A 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 | "\nselect 'foo' as 'bar'\n " |
The other parsers follow the same patterns. Remember that everything in attoparsec is incremental, so we don’t have to worry about boundaries and packets being spread over multiple chunks. The parser is fed until it’s satisfied.
As it happens, for rendering replies to the server, there are
really three server messages of interest. Sending login acceptance,
prelogin acknowledgement, and so-called “general response”, which
is what we’re interested in for the purpose of returning results
from queries. The GeneralResponse consists of a vector
of response tokens Vector ResponseToken. But for this
article, let’s just focus on Row.
data ResponseToken = ... | Row !(Vector Value)
Specifically, the implementation to render a response token is:
renderResponseToken :: ResponseToken -> Builder
renderResponseToken =
case
...
Row vs -> word8 0xD1 <> foldMap renderValue (V.toList vs)
For returning rows for a query, we have Value:
data Value
= TextValue !Text
| BoolValue !Bool
| DoubleValue !Double
| Int32Value !Int32
| Int16Value !Int16
Which is easy to render as a builder:
renderValue :: Value -> Builder
renderValue =
case
TextValue t -> word16LE (fromIntegral (T.length t * 2)) <> byteString (T.encodeUtf16LE t)
DoubleValue d -> doubleLE d
BoolValue b -> word8 (if b then 1 else 0)
Int16Value i -> int16LE i
Int32Value i -> int32LE i
Remember the properties of Builder? It
incrementally builds the data structure. The conduit requesting
chunks from it will request the next chunk, and write that to the
socket. We’ll look at memory use of the server later and confirm
that it’s O(1) in the number of rows.
To handle a connection we have two conduits:
We simply need to consume the incoming stream and dispatch on the message in a loop. Let’s show a more digestible version of that with our simple example we’ve been using.
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import Data.Conduit.Network
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
import Conduit
import Data.Conduit.Attoparsec
main =
runTCPServer
(serverSettings 2019 "*")
(app -> do
putStrLn "Someone connected!"
runConduit (appSource app .| conduitParserEither parser .| handlerSink app))
where
handlerSink app = do
mnext <- await
case mnext of
Nothing -> liftIO (putStrLn "Connection closed.")
Just eithermessage ->
case eithermessage of
Left err -> liftIO (print err)
Right (position, message) -> do
liftIO (print message)
liftIO (runConduit (yield "Thanks!n" .| appSink app))
handlerSink app
parser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
Here’s what’s going on:
(Either ParseError (PositionRange, ByteString)) where
the ByteString is the parsed thing we want.handlerSink which consumes
those parse results one at a time.await produces Nothing, that’s the
end of the stream.eithermessage is Left, then we
have a parse error. We probably want to end here and print the
error. So that’s what we do.Right, then we print out the message, send
back "Thanks" and continue our sink loop.Here’s what the behaviour looks like:
$ cat > writer.hs
main = putStr "5Hello5World"
chris@precision:~$ stack ghc -- writer.hs -o writer -v0
chris@precision:~$ ./writer | nc localhost 2019
Thanks!
Thanks!
C-c
The server reports:
$ ./conduit-atto.hs
Someone connected!
"Hello"
"World"
Connection closed.
Just as we’d expected! The fake SQL Server behaves in the same way, but using the parsers of the packets we’ve looked at briefly, and the renderers we’ve also looked at.
It’s worth taking a moment to digest the accomplishment of being able to handle a binary protocol this trivially. That’s thanks to the abstractions provided by attoparsec and conduit.
Testing was easy because using we’re using high-level abstractions. The conduit handling code is decoupled from the attoparsec parsing code and the rendering code.
myparser parser.For testing random outputs, we can implement an instance of QuickCheck’s Arbitrary,
instance Test.QuickCheck.Arbitrary Value where
arbitrary = oneof [text, int32, int16, double, bool]
where
text = (TextValue . T.pack) <$> Test.QuickCheck.arbitrary
bool = (BoolValue) <$> Test.QuickCheck.arbitrary
double = DoubleValue <$> Test.QuickCheck.arbitrary
int32 = Int32Value <$> Test.QuickCheck.arbitrary
int16 = Int16Value <$> Test.QuickCheck.arbitrary
to generate a random Value for a row column:
> Test.QuickCheck.generate (Test.QuickCheck.arbitrary :: Test.QuickCheck.Gen Value)
BoolValue True
> Test.QuickCheck.generate (Test.QuickCheck.arbitrary :: Test.QuickCheck.Gen Value)
Int16Value 10485
> Test.QuickCheck.generate (Test.QuickCheck.arbitrary :: Test.QuickCheck.Gen Value)
TextValue "2130FcfSI:r*^228185R|239yk246D0~204Z255d138^P"
With this, we can setup a test suite that generates a vector of
values, Vector Value, runs our server, connects to it,
makes a request, makes the server return that vector of values, and
then check that the ODBC library’s returned row matches what we
wanted the server to return. Easy!
Let’s take a look at the memory use of this server. Here’s a simple server that accepts a number of rows to yield, and reads that many rows from a CSV file:
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE TypeApplications #-}
import qualified Data.Map.Strict as M
import Data.Map.Strict (Map)
import Data.ByteString (ByteString)
import qualified Data.Conduit.List as CL
import Data.CSV.Conduit
import qualified Data.Conduit.Binary as CB
import Data.Conduit.Network
import qualified Data.Attoparsec.ByteString as P
import Conduit
import Data.Conduit.Attoparsec
main =
runTCPServer
(serverSettings 2019 "*")
(app -> do
putStrLn "Someone connected!"
runConduit
(appSource app .| conduitParserEither parser .| handlerSink app))
where
handlerSink app = do
mnext <- await
case mnext of
Nothing -> liftIO (putStrLn "Connection closed.")
Just eithermessage ->
case eithermessage of
Left err -> liftIO (print err)
Right (position, lineCount) -> do
liftIO (print lineCount)
liftIO
(runConduitRes
(CB.sourceFile "fake-db.csv" .| intoCSV defCSVSettings .|
CL.mapMaybe
(M.lookup "Name" :: Map ByteString ByteString -> Maybe ByteString) .|
CL.map (<> "n") .|
CL.isolate lineCount .|
appSink app))
handlerSink app
parser = do
len <- P.anyWord8
return (fromIntegral len * 1000)
Here it simply reads a word8 value in from the input as “n
thousand”. We then load up fake-db.csv in a streaming
fashion, converting the bytes into CSV rows, lookup the
"Name" field for each row, if any, append a newline to
each name, and then isolate takes
lineCount results.
Let’s compile this with runtime options enabled:
stack ghc ./sql-dummy.hs --resolver lts-12.12 -- -rtsopts
And run it with statistics output. Here is what happens when we ask for 1,000 rows:
$ ./sql-dummy +RTS -s
Someone connected!
1000
9,149,904 bytes allocated in the heap
36,848 bytes copied during GC
120,112 bytes maximum residency (2 sample(s))
35,680 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 7 colls, 0 par 0.000s 0.000s 0.0001s 0.0001s
Gen 1 2 colls, 0 par 0.000s 0.001s 0.0004s 0.0006s
INIT time 0.000s ( 0.000s elapsed)
MUT time 0.022s ( 4.387s elapsed)
GC time 0.001s ( 0.001s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 0.023s ( 4.388s elapsed)
%GC time 2.4% (0.0% elapsed)
Alloc rate 422,940,926 bytes per MUT second
Productivity 96.2% of total user, 100.0% of total elapsed
And here is what happens when we ask for 2,000 rows, via:
$ printf 'x02' | nc 127.0.0.1 2019
We get:
$ ./sql-dummy +RTS -s
Someone connected!
2000
18,125,240 bytes allocated in the heap
43,656 bytes copied during GC
120,112 bytes maximum residency (2 sample(s))
35,680 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 16 colls, 0 par 0.000s 0.001s 0.0000s 0.0001s
Gen 1 2 colls, 0 par 0.000s 0.001s 0.0003s 0.0006s
INIT time 0.000s ( 0.000s elapsed)
MUT time 0.029s ( 6.247s elapsed)
GC time 0.001s ( 0.001s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 0.030s ( 6.248s elapsed)
%GC time 2.5% (0.0% elapsed)
Alloc rate 628,824,590 bytes per MUT second
Productivity 96.6% of total user, 100.0% of total elapsed
Here are the differences:
That means that we never had to exceed the size of the largest row in the CSV for our total resident memory usage. Perfect for a server that needs to be memory efficient and shuffle lots of data around!
Let’s go back and look at our original goals:
The development experience was smooth because we were able to focus on the things that matter, like the protocol at hand, and not boundaries, buffer sizes, scale problems or memory issues.
If you’re a Haskell company that needs consulting work like this, get in touch!
Subscribe to our blog via email
Email subscriptions come from our Atom feed and are handled by Blogtrottr. You will only receive notifications of blog posts, and can unsubscribe any time.